|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
||||||||
|
|
|
|
|
|||||||
|
|
|
|
|
|||||||
|
|
|
|||||||||
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
||||||||
|
|
|
|
|
|||||||
|
|
|
|
|
|||||||
|
|
|
|||||||||
|
|
|||||
| Benjamin Laxton | Jongwoo Lim | David Kriegman | |||
| University of California, San Diego | Honda Research Institute, Mountain View | University of California, San Diego | |||
|
|
|||||
| CVPR 2007 | |||||
|
|
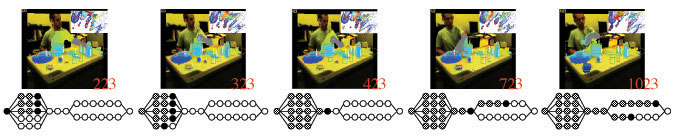
| Here we show a sequence of frames in which a cooking activity is taking place output by our activity recognition system. Below each frame is the current state estimate in the activity graph. |
|
Abstract We present a scalable approach to recognizing and describing complex activities in video sequences. We are interested in long-term, sequential activities that may have several parallel streams of action. Our approach integrates temporal, contextual and ordering constraints with output from low-level visual detectors to recognize complex, long-term activities. We argue that a hierarchical, object-oriented design lends our solution to be scalable in that higher-level reasoning components are independent from the particular low-level detector implementation and that recognition of additional activities and actions can easily be added. Three major components to realize this design are: a dynamic Bayesian network structure for representing activities comprised of partially ordered sub-actions, an object-oriented action hierarchy for building arbitrarily complex action detectors and an approximate Viterbi-like algorithm for inferring the most likely observed sequence of actions. Additionally, this study proposes the Erlang distribution as a comprehensive model of idle time between actions and frequency of observing new actions. We show results for our approach on real video sequences containing complex activities. |
|
Citation Benjamin Laxton, Jongwoo Lim and David Kriegman. Leveraging temporal, contextual and
ordering constraints for recognizing complex activities in video. In the IEEE International Conferance on Computer Vision and Pattern Recognition, 2007.
Paper Overview Video |